 InhaltsverzeichnisAnleitung für Entwickler
InhaltsverzeichnisAnleitung für Entwickler
Datenbanken werden im Yana Framework repräsentiert durch so genannte "Datenbankschemata". Diese Schemata sind Beschreibungen der Struktur einer Datenbank. Das heißt, der enthaltenen Tabellen, deren Spalten, Indexes und Constraints. Diese Informationen werden in Dateien gespeichert. Diese Dateien werden "Datenbankstrukturdateien" genannt und im Verzeichnis "config/db" des Frameworks abgelegt.
Darüber hinaus - und das unterscheidet das Yana Framework grundlegend von anderen Frameworks - enthalten diese Dateien auch die Beschreibung der Semantik einer Datenbank. Das heißt, in welchem Kontext eine Spalte sichtbar oder unsichtbar sein sollte, wie die Informationen für den Nutzer dargestellt werden sollen oder welche Beschriftung die Spalte haben sollte.
Sie benötigen zum Erstellen einer Datenbank für das Yana Framework also kein teures Modellierungswerkzeug und keine SQL-Kenntnisse, sondern lediglich einen einfachen Texteditor.
Um eine neue Datenbank zu erzeugen, öffnen Sie zunächst eine leere Textdatei in PSPad. Stellen die Syntax der Datei auf "Yana Framework" um (sollten Sie den Highlighter und die Code-Templates noch nicht installiert haben, lesen Sie dazu das Kapitel "Editoren für das Yana Framework" ).
Die neue Datenbank wird eine Tabelle "blog" enthalten, welche die Einträge eines Weblogs speichern soll. Jeder Eintrag wird eine eindeutige Id (Primärschlüssel) besitzen, den Namen des Autors, Datum der Erstellung, einen Titel und einen Text.
Bei der Erstellung der Datenbank können Ihnen Code-Templates helfen. Geben Sie den Text "db" ein und drücken Sie die Tasten <STRG> + <SPACE> gleichzeitig. Dadurch wird die Liste der Vorlagen geöffnet. Diese Liste hat zwei Spalten: links in Fettdruck ein "Shortcut", den Sie eingeben können um das Template direkt aufzurufen (wie in diesem Fall "db") und rechts eine Beschreibung des Templates.
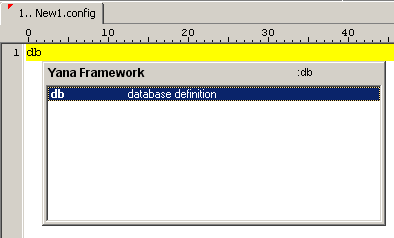
Abbildung: Einfügen von Code-Templates
Wählen Sie die Vorlage "database definition" und drücken Sie <ENTER>. Das Dokument sollte nun so aussehen wie in folgender Abbildung:
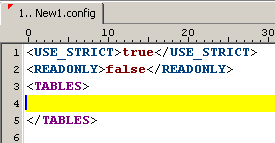
Abbildung: Rumpf der Datenbank
Fügen Sie nun eine Tabelle ein. Drücken Sie dazu <STRG> + <SPACE> und wählen Sie den Eintrag "table definition" (Shortcut "tbl"). Benennen Sie die Tabelle indem Sie den Tabellennamen als Bezeichnung des öffnenden und schließenden Tags einsetzen. In diesem Tutorial soll die Tabelle den Namen "blog" erhalten.
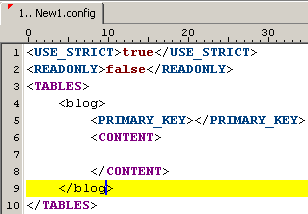
Abbildung: Tabelle "blog"
Fügen Sie der Tabelle nun einen Primärschlüssel hinzu. Eine Tabelle kann stets nur 1 Primärschlüssel besitzen. Der Primärschlüssel muss stets aus genau einer Spalte bestehen und diese Spalte muss vom Typ "integer", "float" oder "string" sein. So genannte "compound primary keys" werden nicht unterstützt.
Um eine Spalte hinzuzufügen, klicken Sie in den Container "CONTENT" der Tabelle und fügen Sie das Code Template "primary key" ein (Shortcut "id"). Nennen Sie die Spalte "blog_id".
Um zu definieren, dass die Spalte "blog_id" ein Primärschlüssel ist, müssen Sie den Namen der Spalte im Feld "PRIMARY_KEY" eintragen.
Haben Sie diese Schritte erfolgreich durchgeführt, sollte Ihre Datei wie folgt aussehen:
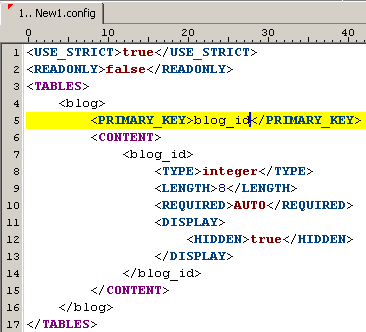
Abbildung: Einfügen des Primärschlüssels
Auf die gleiche Weise fügen Sie nun noch eine Spalte vom Typ "string" für den Titel ein, eine Spalte vom Typ "text" für den Text des Eintrags. Eine Spalte vom Typ "time" für das Erstellungsdatum und eine weitere Spalte vom Typ "string" für den Namen des Autors.
Der Quellcode sollte nun wie folgt aussehen:
<USE_STRICT>true</USE_STRICT>
<READONLY>false</READONLY>
<TABLES>
<blog>
<PRIMARY_KEY>blog_id</PRIMARY_KEY>
<CONTENT>
<blog_id>
<TYPE>integer</TYPE>
<LENGTH>8</LENGTH>
<REQUIRED>AUTO</REQUIRED>
<DISPLAY>
<HIDDEN>true</HIDDEN>
</DISPLAY>
</blog_id>
<blog_title>
<TYPE>string</TYPE>
<LENGTH>255</LENGTH>
<DESCRIPTION>Titel</DESCRIPTION>
</blog_title>
<blog_text>
<TYPE>text</TYPE>
<LENGTH>3000</LENGTH>
<REQUIRED>true</REQUIRED>
<DESCRIPTION>Text</DESCRIPTION>
</blog_text>
<blog_created>
<TYPE>time</TYPE>
<REQUIRED>AUTO</REQUIRED>
<DESCRIPTION>Datum</DESCRIPTION>
</blog_created>
<blog_author>
<TYPE>string</TYPE>
<LENGTH>255</LENGTH>
<DESCRIPTION>Autor</DESCRIPTION>
</blog_author>
</CONTENT>
</blog>
</TABLES>Vergleichen Sie den obigen Quellcode mit Ihrem Ergebnis.
Die Eigenschaft " TYPE " gibt den Typ der Spalte an, " DESCRIPTION " eine Beschriftung der Spalte für den Nutzer. Die Eigenschaft "LENGTH" gibt an wie groß der Inhalt für das Feld sein darf. Bei Spalten vom Typ "string" (in MySQL werden diese als "VARCHAR" umgesetzt) ist dies die Anzahl der Zeichen, welche der Eintrag maximal lang sein darf.
Die Eigenschaft " REQUIRED " gibt an, ob ein Wert zwingend erforderlich ist. Sie kann drei Werte annehmen: "true", "false" und "AUTO". Dabei bedeutet: "true" = ein Pflichtfeld, "false" = eine optionale Angabe und "AUTO" = falls der Nutzer keine Angaben macht, wird der Wert automatisch erzeugt.
Oder anders formuliert: die Eigenschaft "REQUIRED" gibt an, ob eine Spalte "Nullable" ist. Hat "REQUIRED" den Wert "true", wird die Spalte in MySQL zu "NOT NULL" umgesetzt und umgekehrt.
Wenn Sie zum Beispiel den Wert "AUTO" auf eine Spalte vom Typ "integer" anwenden, so erhalten Sie in MySQL eine Spalte, welche das Autoinkrementfeature verwendet. Die Spalte "blog_id" in obigem Beispiel ist somit eine Spalte mit Autoinkrement. (In MSSQL und DB2 wird dies als "Identity", als "Sequenz" in PostgreSQL und in Oracle als Trigger realisiert). Der Wert "AUTO" auf einer Spalte vom Typ "time" bewirkt, dass die aktuelle Zeit als Wert eingetragen wird.
Eine Eigenschaft, welche Sie in dem obigen Beispiel bisher noch nicht verwendet haben, heißt " DEFAULT ". Diese kann verwendet werden, um einen "Defaultwert" anzugeben, welcher automatisch verwendet werden soll, falls der Nutzer keine anderen Angaben macht.
Zum Abschluss, die Eigenschaft " DISPLAY ". Diese Eigenschaft hat keine Entsprechung in SQL. Sie dient der Steuerung der Darstellung der Spalte im Framework. Sie gibt an, in welchen Formularen die Spalte: sichtbar, sichtbar und editierbar, oder nicht sichtbar sein soll. Dabei wird unterschieden zwischen Formularen zum: Anzeigen, Suchen, Erstellen und Editieren von Datensätzen in der Tabelle.
Die obige Tabelle sollte noch um einige Angaben ergänzt werden.
Beispielsweise sollte festgelegt werden, dass die Spalten "blog_title" (Titel) und "blog_text" (Text) immer ausgefüllt werden müssen. Dazu ergänzen Sie die Eigenschaft "REQUIRED" mit dem Wert "true" (Shortcut "req").
Die Angabe zum Erstellungsdatum wird automatisch eingefügt. Sie sollte daher beim Schreiben des Eintrags für den Nutzer nicht sichtbar sein und nicht nachträglich editiert werden können. Fügen Sie für die Spalte "blog_created" (Datum) eine Eigenschaft "DISPLAY" ein (Shortcut "disp"). Setzen Sie die Werte "HIDDEN.NEW" und "READONLY.EDIT" auf "true". Setzen Sie alle anderen Werte auf "false".
Sie können selbstverständlich mehrere Blogs in einer Tabelle speichern. Dazu benötigen Sie eine zusätzliche Spalte, welche identifiziert, zu welchem Blog ein Eintrag gehört. Dies kann zum Beispiel nützlich sein, falls Sie mehrere Webseiten haben und pro Webseite einen eigenen Blog speichern möchten.
Die Unterscheidung in mehrere Blogs und die Zuordnung zu einzelnen Webseiten müssen Sie nicht von Hand programmieren. Das Framework besitzt für diesen Zweck ein vorbereitetes Template.
Fügen Sie zunächst eine neue Spalte vom Typ "profile" ein (Shortcut "pid"). Die Spalte sollte den Namen "profile_id" haben. Anschließend fügen Sie für die Tabelle, unter der Eigenschaft "PRIMARY_KEY" die Eigenschaft "PROFILE_KEY" ein (Shortcut "prf") und setzen den Wert dieser Eigenschaft auf den Namen der Spalte: "profile_id".
Vergleichen Sie Ihr Ergebnis mit dem folgenden Quellcode.
<USE_STRICT>true</USE_STRICT>
<READONLY>false</READONLY>
<TABLES>
<blog>
<PRIMARY_KEY>blog_id</PRIMARY_KEY>
<PROFILE_KEY>profile_id</PROFILE_KEY>
<CONTENT>
<blog_id>
<TYPE>integer</TYPE>
<LENGTH>8</LENGTH>
<REQUIRED>AUTO</REQUIRED>
<DISPLAY>
<HIDDEN>true</HIDDEN>
</DISPLAY>
</blog_id>
<blog_title>
<TYPE>string</TYPE>
<LENGTH>255</LENGTH>
<DESCRIPTION>Titel</DESCRIPTION>
<REQUIRED>true</REQUIRED>
</blog_title>
<blog_text>
<TYPE>text</TYPE>
<LENGTH>3000</LENGTH>
<REQUIRED>true</REQUIRED>
<DESCRIPTION>Text</DESCRIPTION>
<REQUIRED>true</REQUIRED>
</blog_text>
<blog_created>
<TYPE>time</TYPE>
<REQUIRED>AUTO</REQUIRED>
<DESCRIPTION>Datum</DESCRIPTION>
<DISPLAY>
<HIDDEN>
<NEW>true</NEW>
</HIDDEN>
<READONLY>
<EDIT>true</EDIT>
</READONLY>
</DISPLAY>
</blog_created>
<blog_author>
<TYPE>string</TYPE>
<LENGTH>255</LENGTH>
<DESCRIPTION>Autor</DESCRIPTION>
</blog_author>
<profile_id>
<TYPE>profile</TYPE>
<LENGTH>128</LENGTH>
<REQUIRED>AUTO</REQUIRED>
<DISPLAY>
<HIDDEN>true</HIDDEN>
</DISPLAY>
</profile_id>
</CONTENT>
</blog>
</TABLES>Damit ist das Erstellen der Datenbank abgeschlossen. Speichern Sie Ihre Änderungen unter der Datei "blog.config" und schließen Sie das Programm.
Falls Sie sich tiefer mit den in diesem Abschnitt behandelten Themen beschäftigen wollen, finden Sie Anleitung in folgenden Artikeln:
Der folgende Abschnitt wird sich mit der Erstellung des Programmcodes beschäftigen.
 Thomas Meyer, www.yanaframework.net
Thomas Meyer, www.yanaframework.net
 Kapitel 1: Vorbereitung
Kapitel 1: Vorbereitung